Practical implementations of Newton's method on Deep Neural Network (in progress)
Stochastic gradieng (SG) methods are currently the major optimization method being used for deep learning because of the simplicity and efficiency. However, the method is sometimes sensitive to parameters and their tuning can be a painful process. To alleviate the above issues, we study the Newton’s method for training Deep Neural Networks (DNN), which can not only diminish the need for hyper-parameter tuning but also emjoy the benefit of fast convergence for convex functions.
We have developed a toolkit in Tensorflow and MATLAB for DNNs using Newton-CG methods. For the core operation of Gauss-Newton matrix-vector products, I use Tensorflow’s vector-Jacobian products. See implementation details in this document.
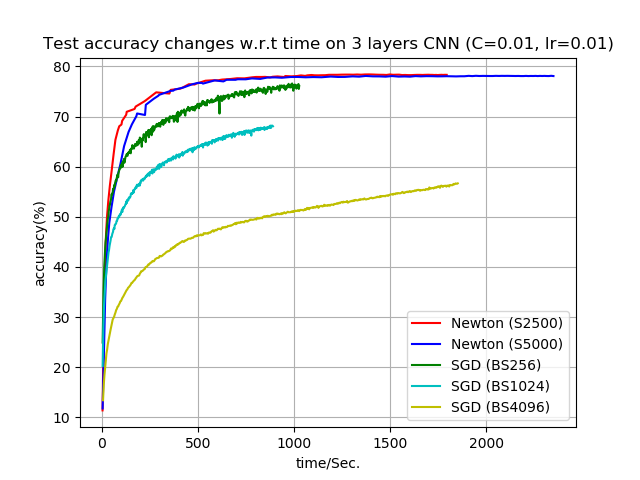
Accuracy on 3-layer CNN
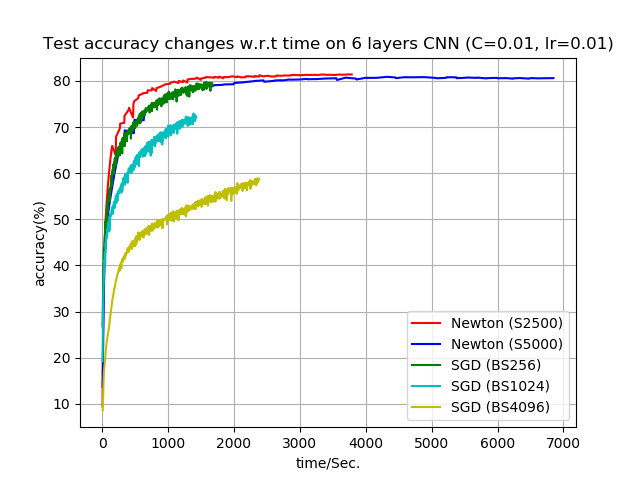
Accuracy on 7-layer CNN
I also gave a presentation on this project. Codes are available at SimpleNN.