Reviews on second order optimization methods for deep learning
I mainly inverstigate different second-order optimization methods in DNN in a stochastic manner, including Trust-region Method (TR) and (adaptive) Cubic Reg- ularization (CR), and compared their convergence rate, generalization error and computation efficiency with SGD.
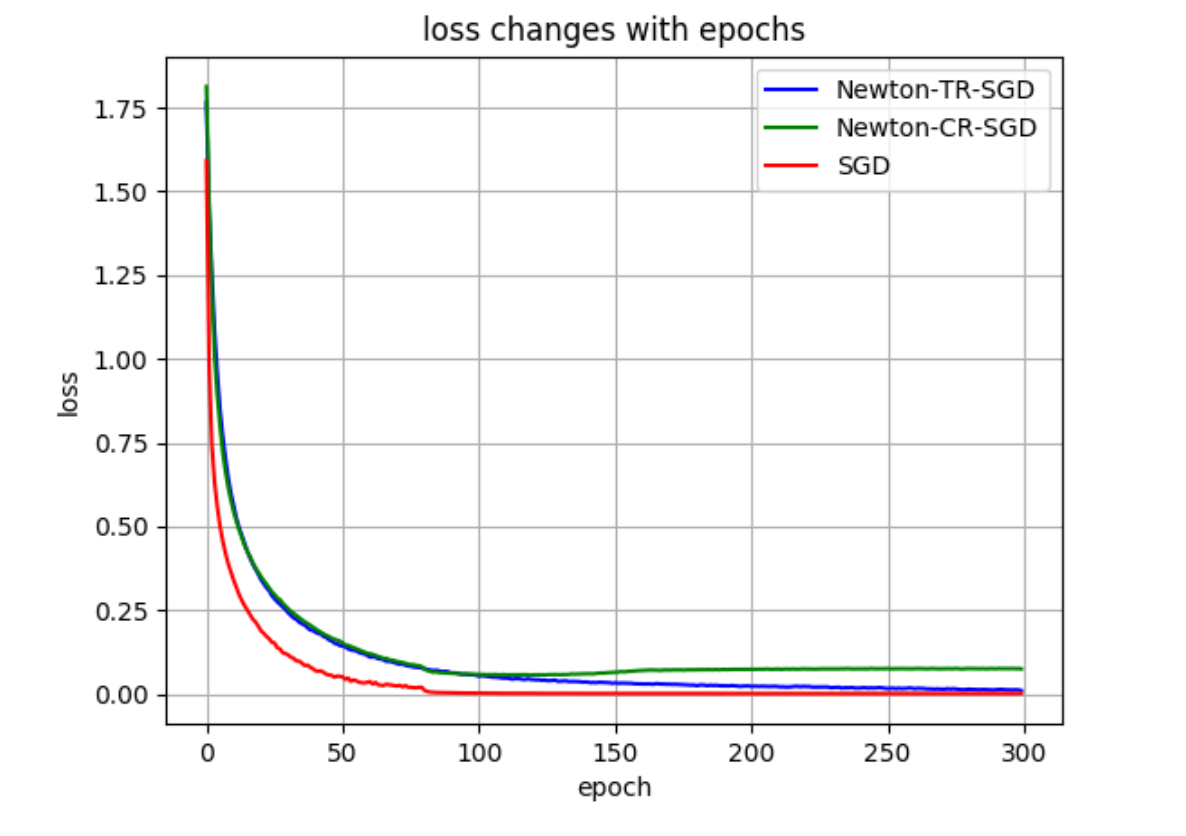 Training loss of SReLU-ResNet
Training loss of SReLU-ResNet
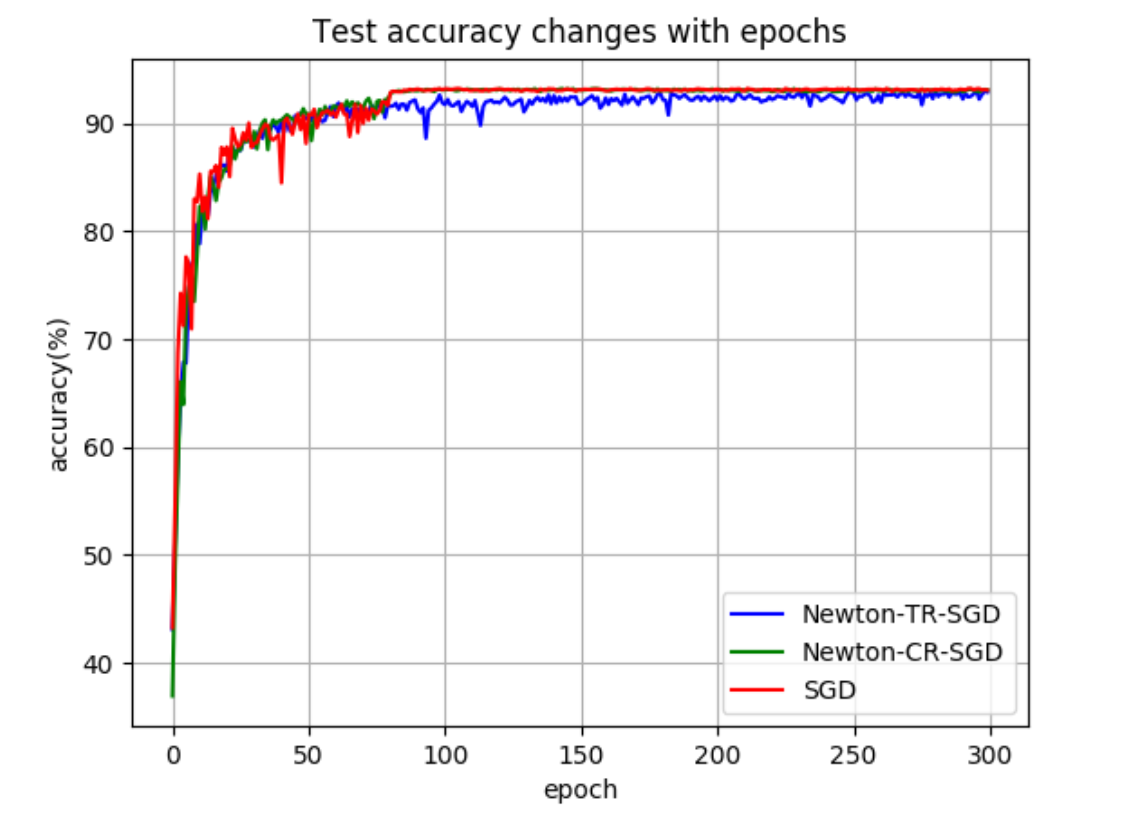 Test accuracy of SReLU-ResNet
Test accuracy of SReLU-ResNet
I use the gradient based solver to solve each the inner optimization problems for both TR and CR problem. The method can effectively converge to a local minimum that has similar performance as SGD. However the overhead in each step is significant. I also compared LBFGS and Newton-CG methods in the project. The inferior performance may be caused by the noisy estimation of Hessian term.
Codes are available at Github. Experiment details are summarized in the report.